Today
Expert systems, an integral part of AI, are one of the best examples of rules-based programming. The core idea is to have a computer system that can provide the same depth of knowledge as top-notch human experts on a field-by-field basis. In theory, I should be able to build one of those beasts for health, for example, while someone else could have one on engineering or business management. And so on and so forth. Producing a single one for all fields was still a pipedream at the time. Regardless, expert systems had a relatively short Belle Epoque in the 1980s and then returned to oblivion.
Simplifying a bit, an expert system must first create a comprehensive knowledge base of the targetted area. It must then build a complex set of rules to identify, compile and extract the precise information end-users seek in real time. Unlike the traditional programming structure showcased in the first part of this post, data (information, knowledge) plays a quintessential role here, as the quality of the output yielded by the elaborate set of rules depends on its quality and depth. Rules alone cannot improve such quality. Building the best possible knowledge base is, therefore, critical for success. That, in turn, demands lots of human and computational resources. And as a programmer, I have to develop a comprehensive set of rules that cover all possible options to generate the most accurate response. That is indeed an incredibly complex task, very hard to achieve within 1980s computing structures.
Let us not forget that at the height of their prime, decades before big data, data collection and storage were costly and cumbersome, sophisticated computing capacity was expensive, and microchips were still taking baby steps. Expert systems were swimming against the tide, albeit always ahead of their time. In sharp contrast to traditional programming, they demanded much more coding and algorithm development, in addition to substantial efforts to build state-of-the-art knowledge bases. That was programming on steroids, so to speak.
The tide started to change twenty-plus years later, with AI’s Renassaince having an almost immediate and indelible impact on programming. Spearheaded by new Machine Learning (ML) algorithms that piggybacked on an overabundance of data, facilitated by cheap collection, storage and distribution networks, and unparallel computing power, mainly available to the new and humongous corporations that still dominate the digital computing scene.
The figure below depicts, with some simplifications, the typical ML computing process. I have also inserted a thumbnail of the scheme for traditional programming in the top right corner so we can easily visualize the differences.
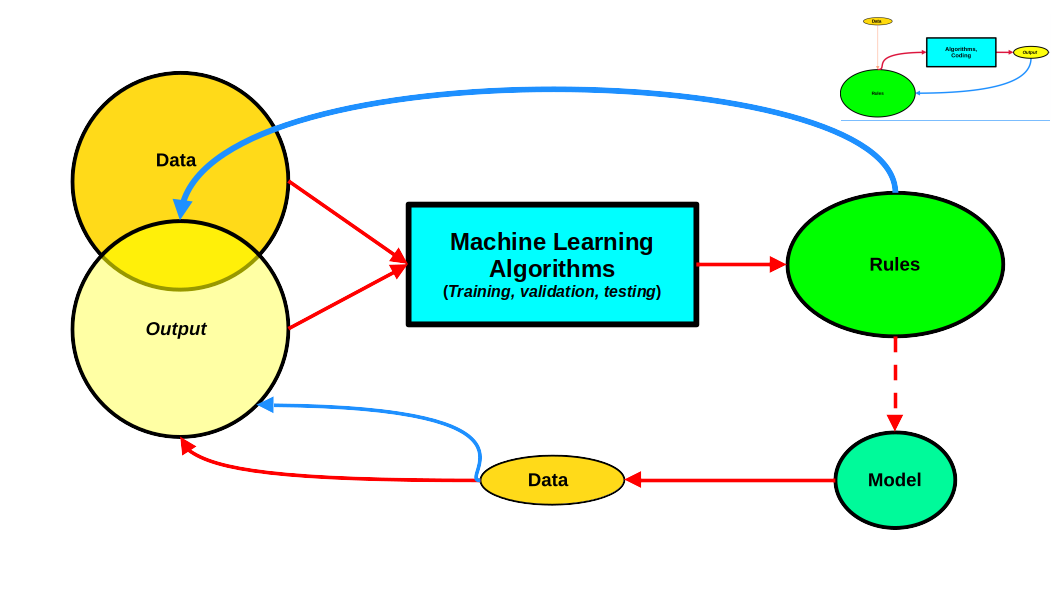 In most cases, data in ample quantities is the departing point. That is certainly the case for both supervised and unsupervised learning. Alternatively, some reinforcement learning models can start with little data and then generate new data endogenously. That is undoubtedly the case for AlphaGo and AlphaZero, for example. Unsupervised data can successfully consume data directly, assuming it has been appropriately cleaned by humans, without us having to tell it what each data point represents. On the other hand, supervised learning is the opposite. It needs to be told what the data is; thus, labeling becomes an essential component. In this process, humble humans (not computers or AI), usually paid peanuts for the work, also play a critical role. Once the labeling is completed, we can say that we are feeding ML the output we want it to master.
In most cases, data in ample quantities is the departing point. That is certainly the case for both supervised and unsupervised learning. Alternatively, some reinforcement learning models can start with little data and then generate new data endogenously. That is undoubtedly the case for AlphaGo and AlphaZero, for example. Unsupervised data can successfully consume data directly, assuming it has been appropriately cleaned by humans, without us having to tell it what each data point represents. On the other hand, supervised learning is the opposite. It needs to be told what the data is; thus, labeling becomes an essential component. In this process, humble humans (not computers or AI), usually paid peanuts for the work, also play a critical role. Once the labeling is completed, we can say that we are feeding ML the output we want it to master.
In all cases, ML algorithms then process data in an iterative process where feedback between the rules the algorithm generates and the data is crucial. Optimization techniques, statistical analysis, and inference play a central role in this process. Once we are satisfied with the set of rules, we have a model that can be deployed for public consumption and handle new data streams, usually of a much smaller scale. The output of this last step either falls within the confines of the original data or might suggest glaring gaps that will require running the whole process all over again. In this way, the model can keep learning new rules ad infinitum, at least in theory.
As a coder, my role has now changed substantially. I am no longer the rules master. Instead, my efforts are now centered on programming a computational agent capable of developing such rules. In other words, I am now the teacher of an intelligent computer agent who, in principle, can make decisions independently. But now, in addition to coding, I need to dig deeper into the mathematical intricacies of the various ML algorithms I can deploy and master data analytics and statistical analysis. The decision to release the ML model for public use is made by humans and, in principle, depends on its statistical accuracy. Not that anyone is independently checking, so finding pretty inaccurate ML models deployed in private and public entities should not be surprising.
In this light, I must conclude that programming has dramatically changed since I wrote my first straightforward piece of code. Moreover, the re-emergence of ML in the last decade or so has propelled such a transformation that is still ongoing.
Tomorrow
ChatGPT has taken the world by storm. It has already set the record as having the fastest user base in history – 100 million users in just two months and counting. It can translate, summarize, manage Q&A sessions and write on our behalf. Almost like a sound old expert system but more intelligent and universal. Some argue that technology is the prelude to AGI, Artificial General Intelligence. Others call it a general-purpose technology that can be deployed anywhere and everywhere. In all cases, ChatGPT and competitors will bring even more dramatic changes to computer programming.
The ML model behind ChatGPT and Friends is called Transformers, paradoxically created by Google Brain in 2017. I guess Google fell asleep at the wheel. If you want to understand transformers, look at this paper, for example. Knowing any programming language, Python included, will not help you much in mastering such a model. But of course, we do not need to fully understand transformers to write code to support their development and implementation. But then again, my role as a coder is not traditional. In fact, I am coding an agent that can code itself and yield the expected outputs. It is not out of the question that we can also have computational agents doing most of that work shortly.
Does this mean that programming will disappear in the next few years? Although I am not great at making predictions, I would argue that coding will still be around, albeit with a very different kind of life. First, traditional programming will still be around for a time but will be pushed to the fringes. Something similar happened with Vynil when the “CD revolution” took over the recording industry. However, Vynil is making a comeback while online music subscriptions are leading the field. However, I do not think old programming will be able to make a Vynil comeback. Second, programming will become a more sophisticated field demanding a combination of different advanced skills and coding. More so if ML algorithms continue to become more complex. Third, programming will become a more stratified field, with those working in leading-edge companies and Big Tech reaping the most of the benefits. At the same time, tasks ML cannot directly do will be undertaken by humans, who will even see lower rewards per task completed. Fourth, hacking and hackers will become more scarce as the skills needed to hack into ML platforms will increase in complexity. Old hackers will have to transition or move to a different field of work. In any event, hackers will not be the change agents of the digital world, as suggested by some academics.
Finally, I do not know if any of the above will happen. But I am absolutely sure my days as a programmer are long gone. No comeback is possible.
Raúl
