TechPlus+ | Technology & Development Redux
-

Major Minor Metals
Read more: Major Minor MetalsEven though it could not be avoided, I still daydreamed about skipping it. I was getting ready to start my last two years of high school, and the curriculum pinpointed chemistry and physics as my tallest hurdles ahead. If I had a choice, I would have opted for physics as I was already familiar with…
-
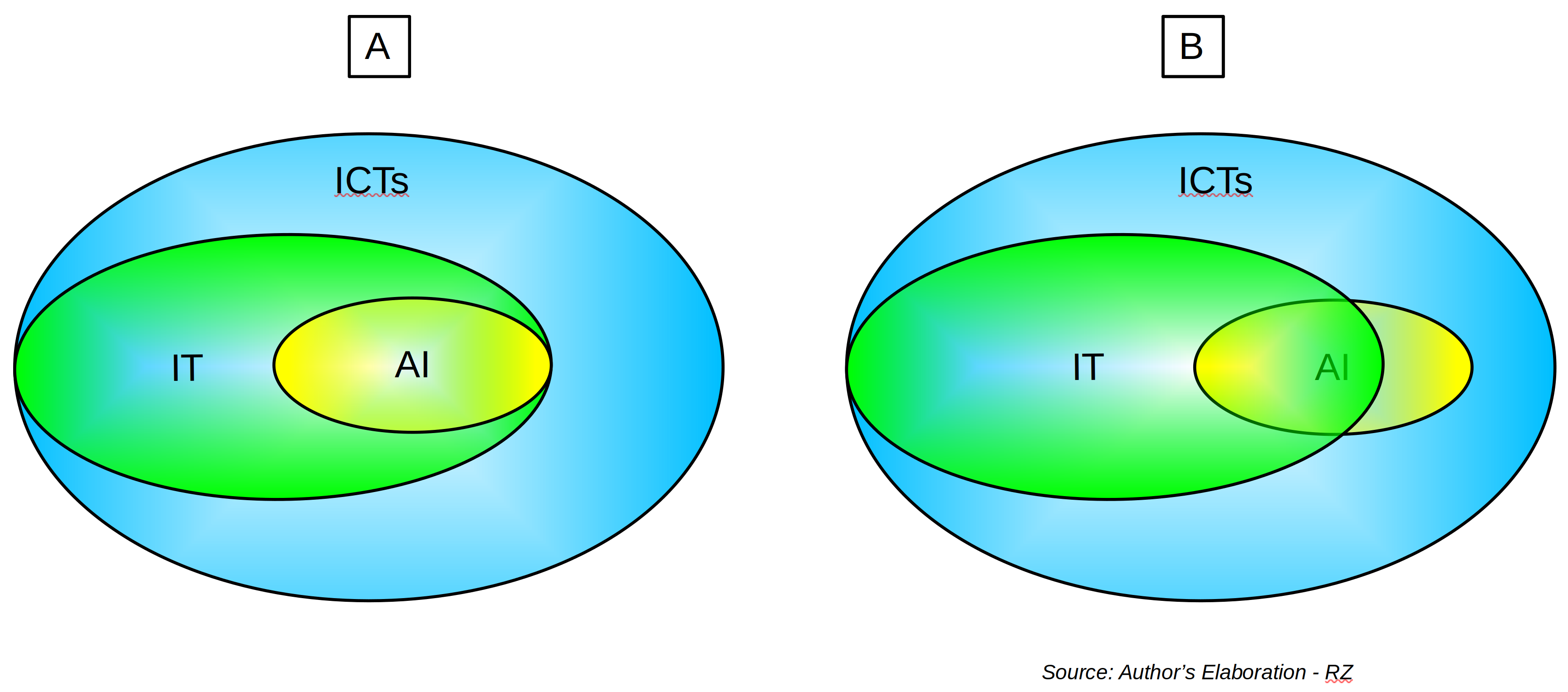
AI and ICTs
Read more: AI and ICTsIs AI an ICT? It sounds like a straightforward question. But before we dive into those seemingly shallow waters, let us tackle acronym abuse. I hope to use four consistently: AI (Artificial Intelligence), Gen AI (Generative AI), IT (Information Technology), and ICTs (Information and Communication Technologies) – while adding a few more along the way.…
-

Generative AI (GenAI) in the Public Sector
Read more: Generative AI (GenAI) in the Public SectorIt was a last-minute decision. The annual New York Film Festival was underway, and I had carefully studied its lineup. My list had four options: 1. Must see. 2. Should see. 3. See some time later on. And 4. Not really interested. The film playing that day was part of the second set. Sixty minutes…
-

Regulating AI
Read more: Regulating AIThe EU’s December agreement on legislation tackling AI deployment and use in the Union and beyond is yet more evidence of its global leadership in the area of digital technology regulation . A few weeks before the epic event, heavy lobbying by the usual suspects had placed the legislation’s future on the line . Generative…
-

Decolonizing AI
Read more: Decolonizing AIJust like the Internet, the origins of Artificial Intelligence (AI) are linked to wars and ensuing military operations. In this case, WWII was the critical catalyst in supporting the research efforts of early pioneers such as Turing, Shannon and Wiener. Building on Turing’s theory of computation and recent developments in mathematical modeling, two academic researchers…
-

Best Films – 2023
Read more: Best Films – 2023This was a blockbuster year for two non-competing films launched almost simultaneously. Even my favorite art house joint fell for them, no questions asked. One dealt with a skinny doll and was financed by the large corporation that makes such toys, now including all colors and sizes, of course. Sadly, many white feminists decided the…
-

Regulating Digital Platforms – IV
Read more: Regulating Digital Platforms – IVThat the EU is well ahead of the rest of the world regarding digital technology regulation is not under dispute . The recent agreement on AI regulation provides further evidence of its leadership . A more interesting question is why the Union has not been able to give birth to digital platforms and companies that…
-
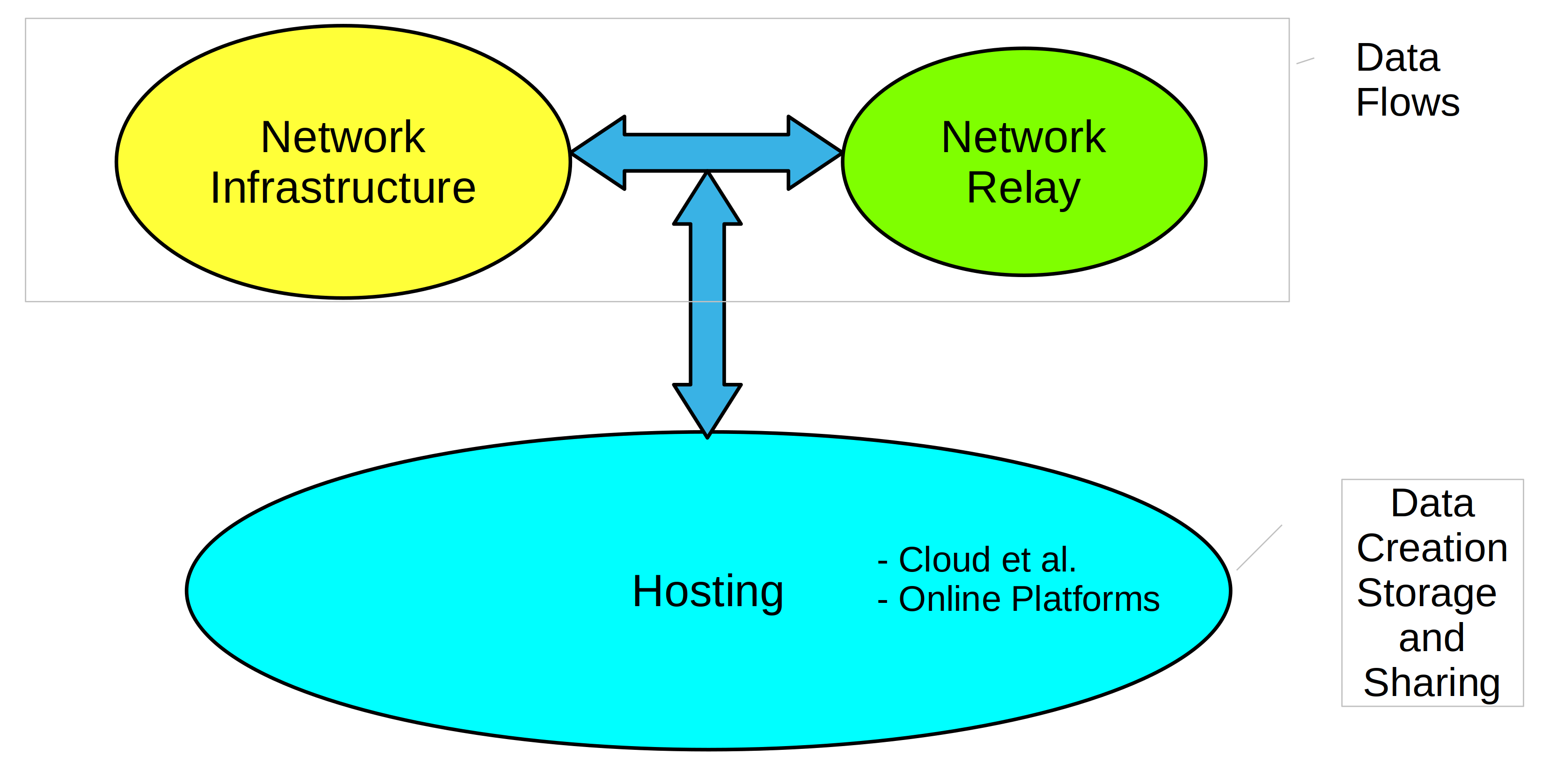
Regulating Digital Platforms – III
Read more: Regulating Digital Platforms – IIIDigital platforms are a particular case of the broader platform category and thus have distinct characteristics. At the same time, they come in different forms and shapes. Putting them into a single box is not a piece of cake. Indeed, the devil is in the details. That is undoubtedly a challenge for policymakers and regulators.…
-

Regulating Digital Platforms – II
Read more: Regulating Digital Platforms – IIAs suggested in the first part of this post, not all platforms are digital. In fact, analog platforms are the older siblings. Its digital counterparts are undoubtedly distinct, their calling card usually being their multisided nature – operating in more than one two-sided market. However, analog multisided platforms have also existed for a long time…
-
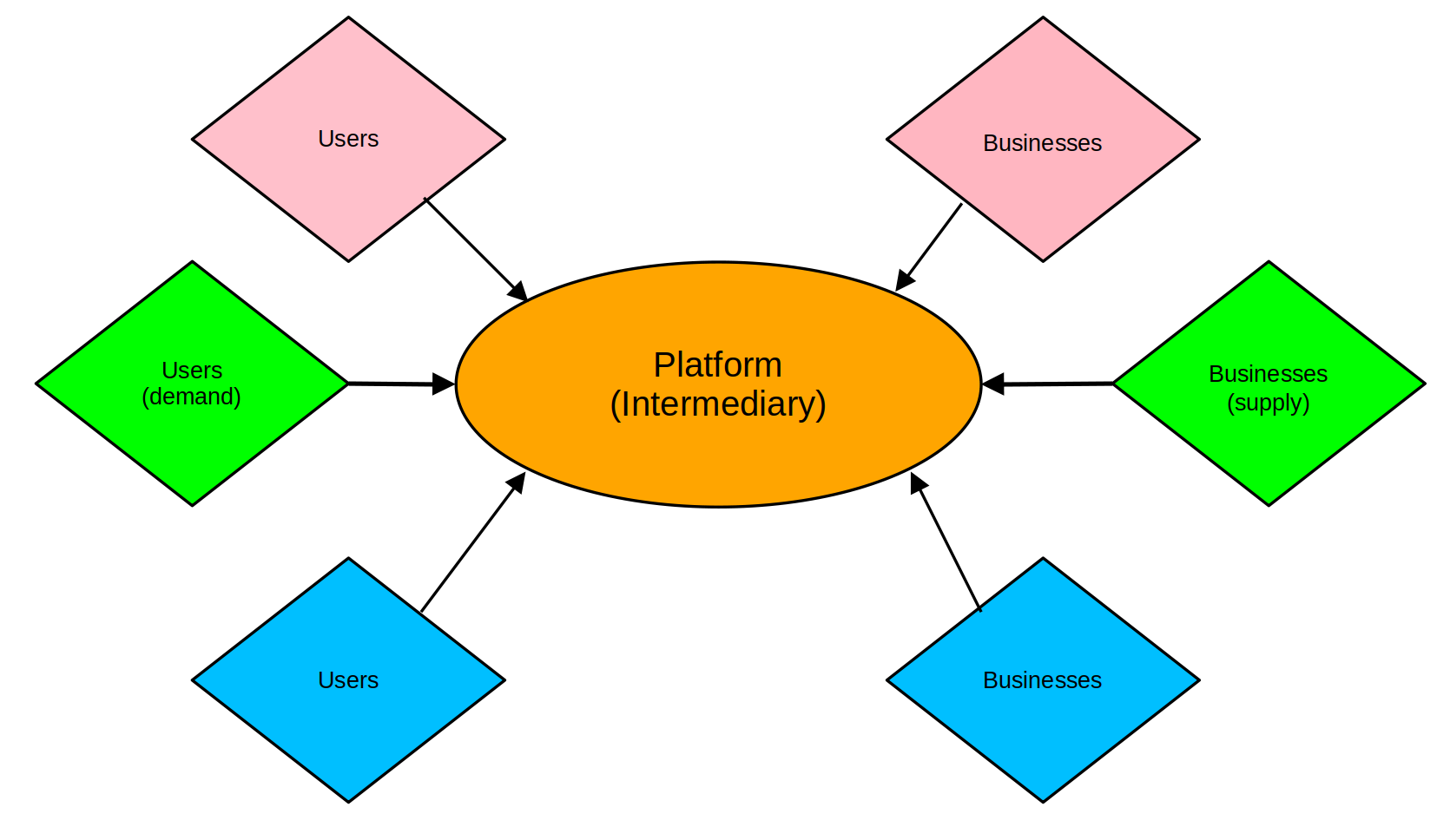
Regulating Digital Platforms – I
Read more: Regulating Digital Platforms – IBy all accounts, the regulatory tide, constantly receding for so many years, is finally returning to the digital realm’s now extensive and arid shores . Indeed, digital platforms are now under the policy microscope, especially the well-known global giants whose names I do not need to echo here. These behemoths are carrying the day with…
-

AI Disinformation – II
Read more: AI Disinformation – IIAI’s astounding evolution in the last decade has been nothing less than spectacular, pace doomers. It has undoubtedly exceeded most expectations, bringing numerous benefits and generating new challenges and risks. The latter is crucial to understand as AI has a bi-polar personality. It is indeed friend and foe. It all depends on how humans (ab)use…
-

AI Disinformation – I
Read more: AI Disinformation – IThe idea of a technological singularity has been around for over 60 years. While initially confined to closed circles of experts, it has been gaining a lot of ground in the race to the future, which, according to its core tenets, will be devastating for us, poor dumb humans. I probably first heard about it…
-

Organized Disinformation – II
Read more: Organized Disinformation – IIBubble inhabitants live in a world surrounded by an invisible yet effective firewall that protects them from allegedly vicious external sources, disinformation included. In such a paradise, harm is almost always pushed back if it attempts to cross it. And bliss emerges in a world of subtle, ample ignorance. While many might know they live…
-

Organized Disinformation – I
Read more: Organized Disinformation – II still remember the phone number of the line my parents somehow managed to get installed in their first-owned house, a three-story dwelling my father, a civil engineer, helped design and build for a family of seven. It had six digits, which seemed like one too many. When asked, my father said the reason was…
-
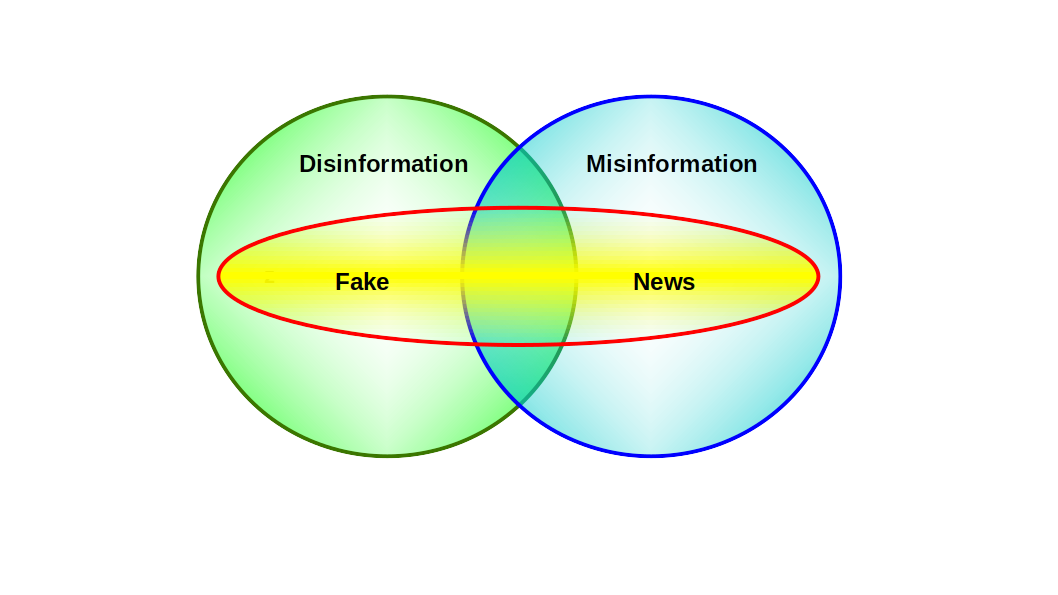
Disinformation Misinformation
Read more: Disinformation MisinformationThe rainy season had already begun but, as usual, did not provide any relief from that sweltering heat that never abandoned the small rural town. It was a regular Thursday morning, and Cesar planned to head back to the farm riding his mule, always carrying his shotgun. One never knows what might happen along the…