Category: Artificial Intelligence
-

Brilliant AI Chatbots
Just over a decade ago, we could not stop talking about surveillance. Indeed, the 2013 Snowden files revealed a series of spook technologies that most people had only seen in largely mediocre Hollywood films, always with a reference to the Stasi or “communism,” of course. So-called “democracies” will never do that was the implicit, subliminal…
-
Clouds in the Cloud – II
Talk about an ongoing AI bubble seems to be getting louder by the minute. As previously mentioned, estimates indicate that by 2030, close to 7 trillion USD will be invested in the sector—assuming the bubble will not burst in the interim. Most of this massive investment is expected to go toward digital infrastructure, led by…
-
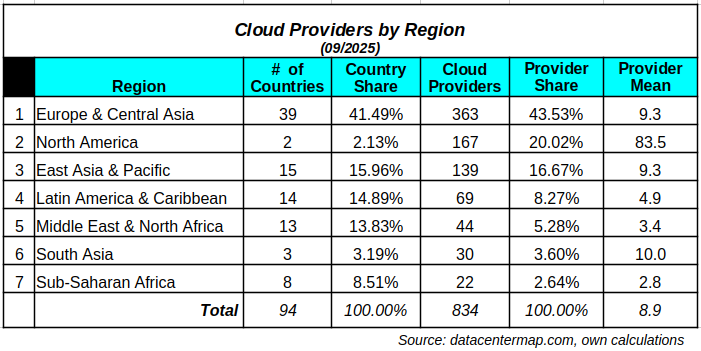
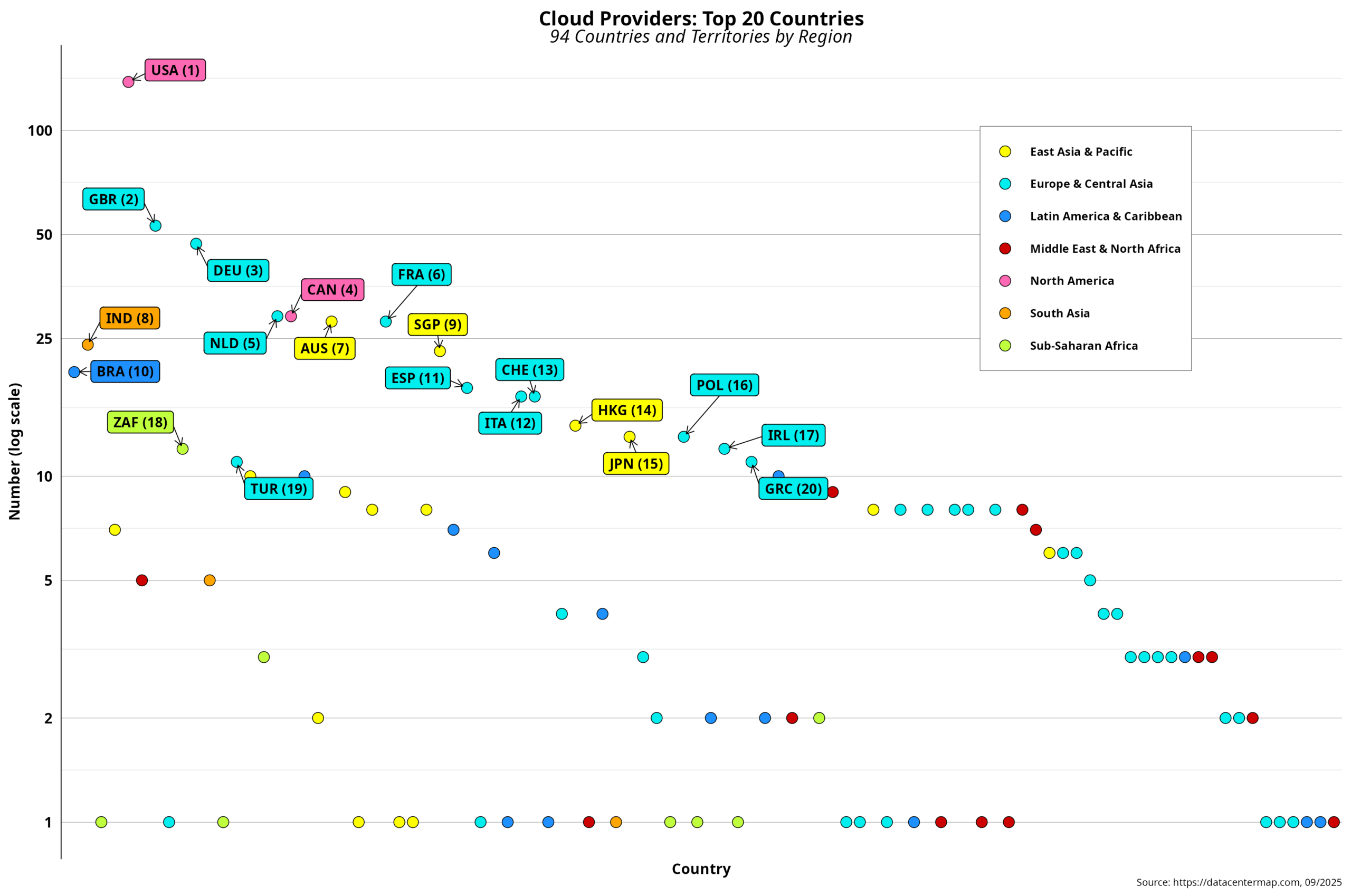
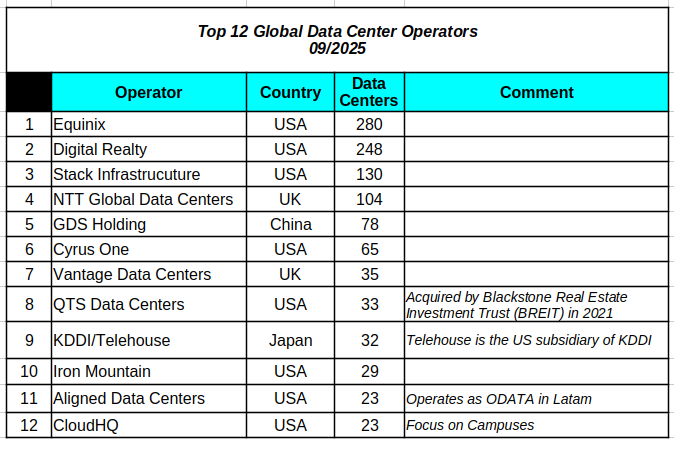
Clouds in the Cloud – I
Now that we have a clearer picture of the uneven distribution of data center locations, we can take a closer look at cloud providers. The first step here is to conceptually differentiate between data centers and cloud providers. Recall that the business literature states that cloud providers are one of the five types of data…
-

Data Center Resistance
Two weeks ago, Mexico announced a 4.8 billion USD data center investment sponsored by CloudHQ, one of the top 12 operators globally by number of sites. The target geography is Querétaro, the leading Mexican data center location with 19 facilities. Querétaro is also among the top 15 developing-country towns in the data center race. The…
-
Data Center Centralization – IV
The last time I visited Eswatini was in late 2019, three months before the COVID-19 pandemic almost brought our collective imagination to a halt. Digital government support was the excuse for the business trip. I had been there a couple of times before and was thus familiar with the territory. Elections held the previous year…
-
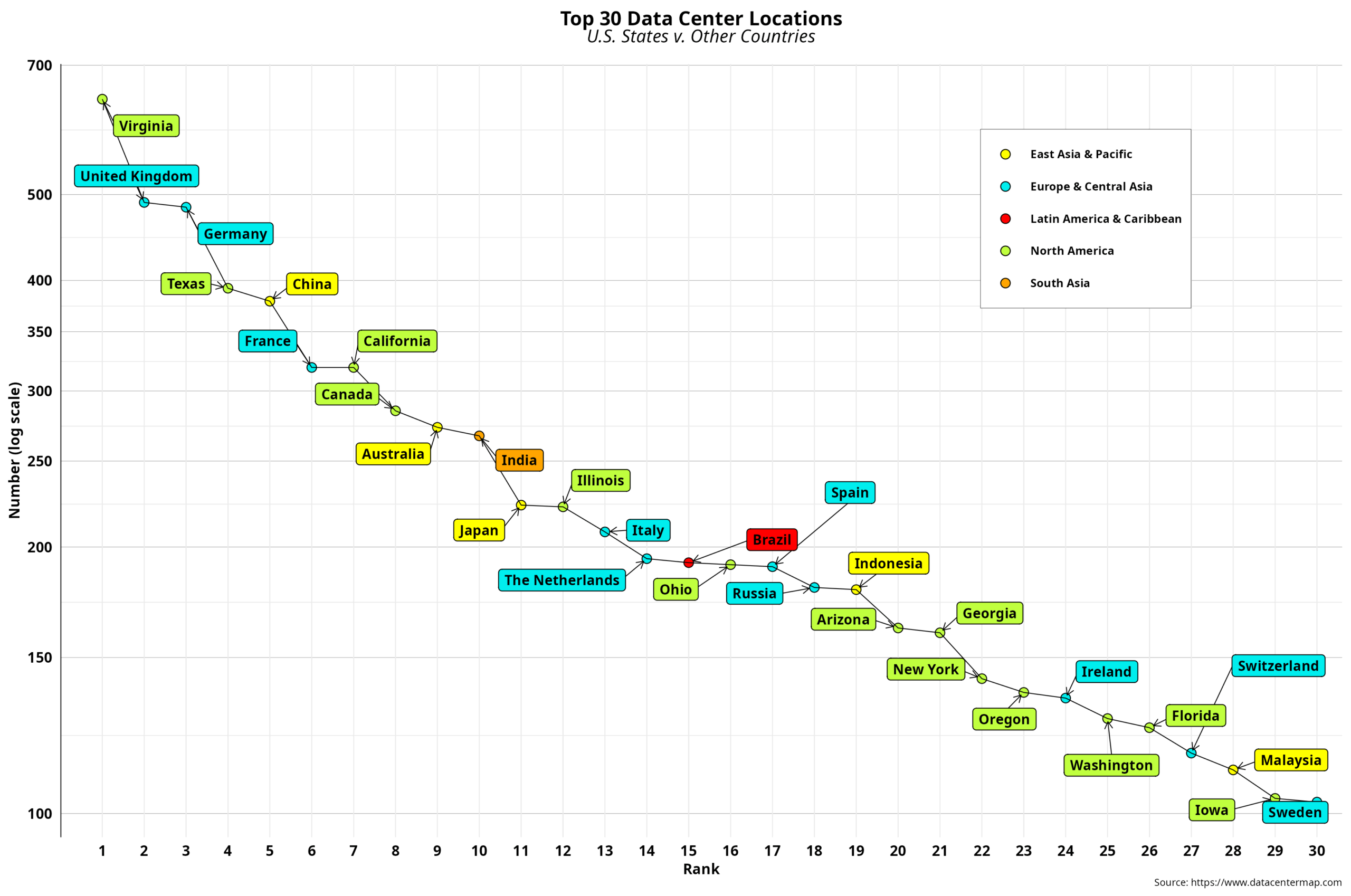
Data Center Centralization – III
Country data typically provides a comprehensive macro overview of the current status of a particular theme, such as data centers in our case. The same goes for CO2 emissions, for example. On the other hand, countries are geographical abstractions that posit the topic within well-defined boundaries, where a national state exercises its sovereignty to the…
-
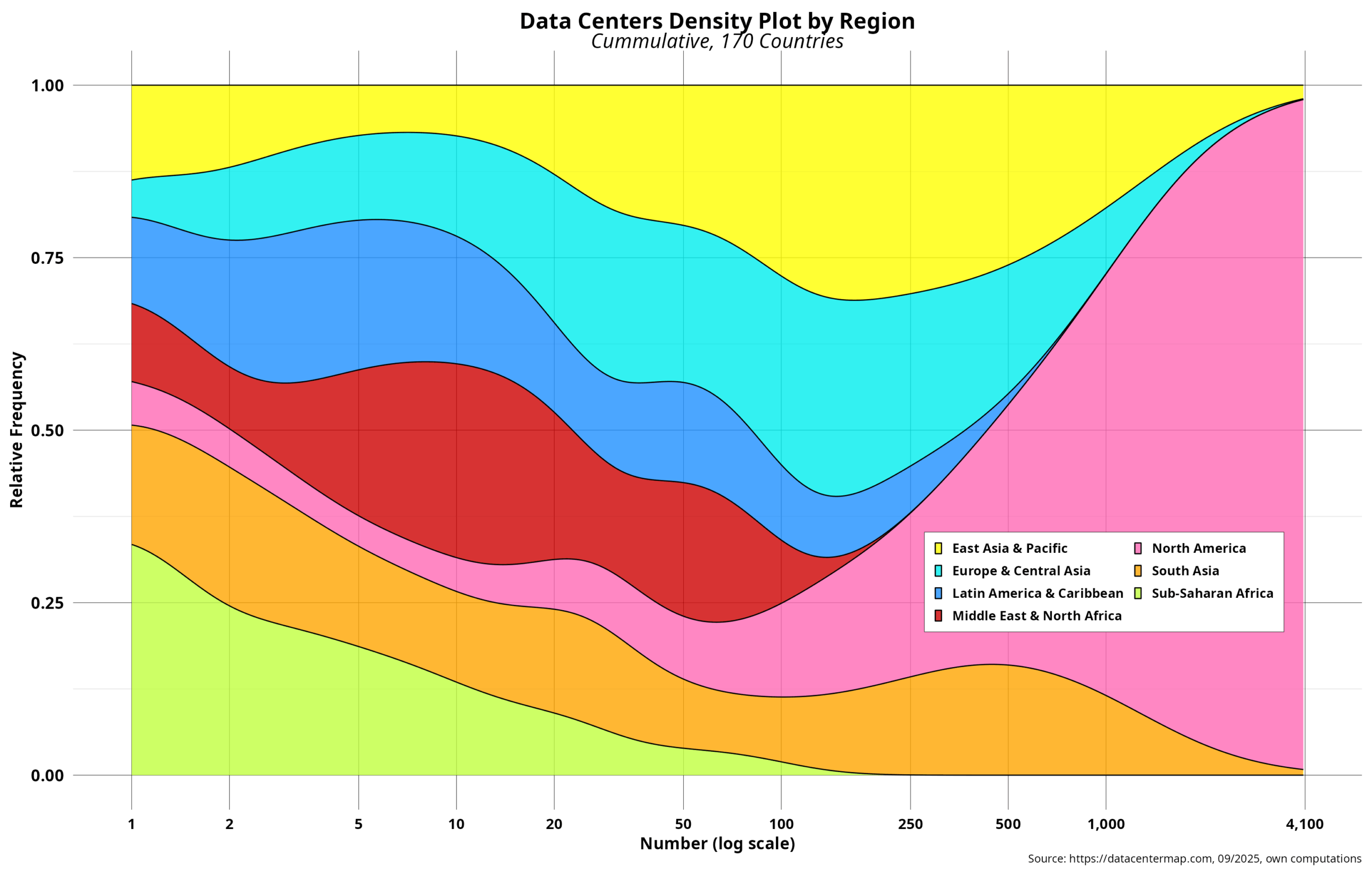
Data Center Centralization – II
By now, we are aware that data center deployments have a clear geographical bias. Indeed, one region is significantly ahead of the rest. Those comprised of mostly industrialized countries follow, albeit at a considerable distance. The rest can hardly breathe. In any case, such patterns could serve as the first clue about which areas are…
-
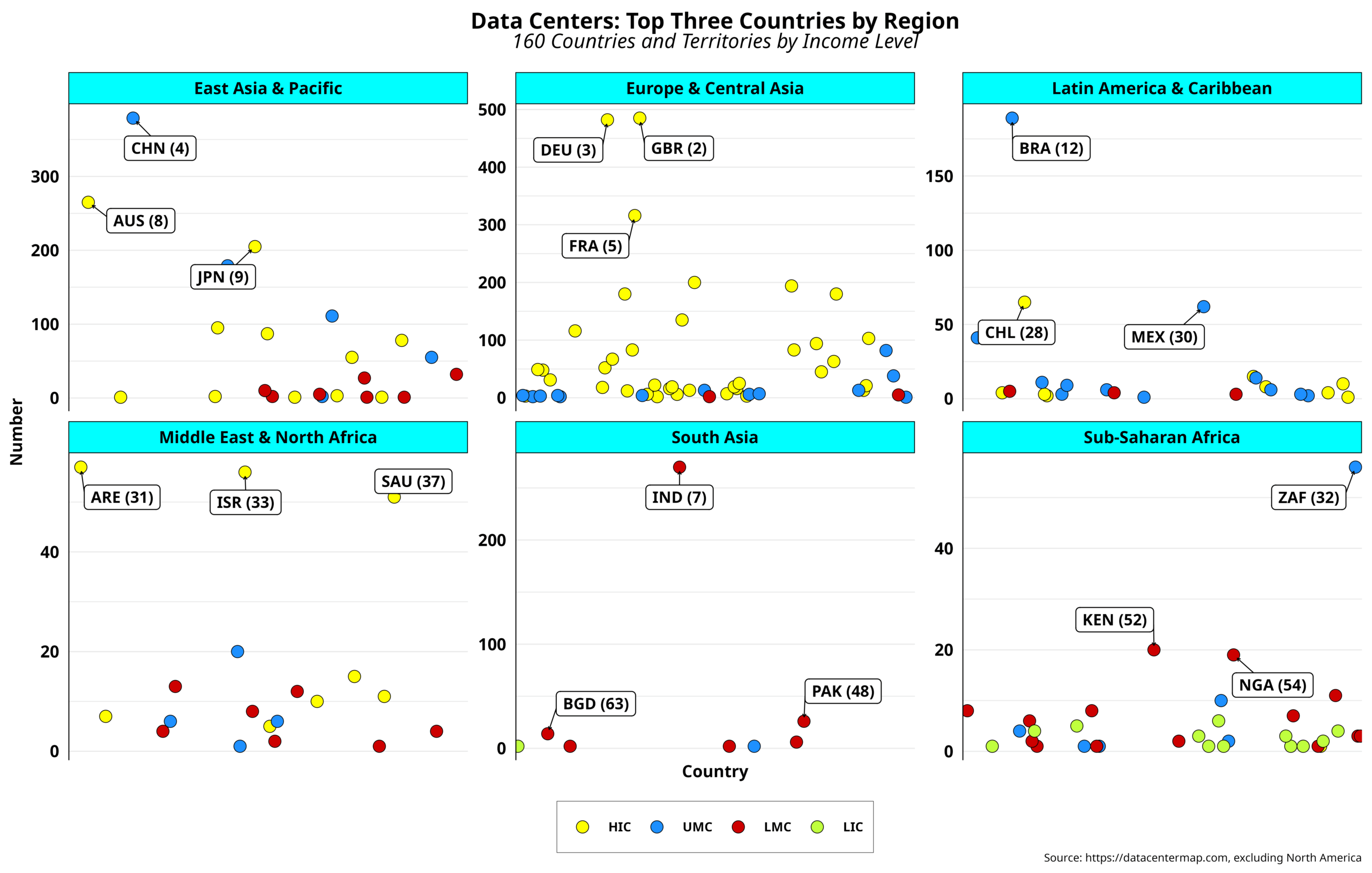
Data Center Centralization – I
As mentioned in the previous post, capital investments in data centers are expected to hit record sums. Predictions for 2030 suggest that nearly 7 trillion dollars will be heading that way, with 25 percent of that amount allocated to energy resources alone. Indeed, Big Tech is not expected to be the only player in this…
-

Data Center Centrality
Recent headlines have put the spotlight on Big Tech’s investment trends in data centers. While the gang of five has already spent $155 billion on data center expansion since January, the total annual amount for this year is expected to reach $365 billion. That is more than the nominal 2023 GDP of over 150 countries,…
-

Laboring AI – II
Research on the labor impact of GPTs is mainly focused on advanced economies in the West. Implicitly, it is assumed that what thrives in the former should also blossom in all other nations, provided they have reached a certain level of development and have been able to actively integrate into the global economy. The rest…
-

Laboring AI – I
The sudden resurgence of AI in the early 2010s, riding on the coattails of newly developed and groundbreaking machine learning and deep learning algorithms, was accompanied by the emergence of seemingly endless “future of work” conversations and, eventually, heated debates . By the end of the decade, generating target listings by job and/or sector had…
-

Free Market Dependency
I have previously argued that Big Tech companies with unbreakable ties to the real economy are more prone to incessant competition from both incumbents and non-incumbents. Apple and Amazon’s signature products are the best examples here. Take the iPhone. It not only has to deal with the Android caterpillar globally but also faces formidable competition…
-

Sizing up Big Tech – VI
While it may be convenient to categorize the five usual suspects under the Big Tech label, ignoring the differences between them, pointed out in previous posts, could lead to simplistic conclusions. Take the word “big.” How big is “big?” The most common parameter used to measure is market capitalization, which is consistently in the trillions of…
-

Sizing up Big Tech – V
Connecting to the Internet in 1994, the year Amazon was founded, was certainly not a walk in the park. For starters, the number of access providers could be easily counted. Accessing the emerging network of networks from home required a computer, a modem, an RS-232 compatible cable, supporting software, and an additional phone line, depending…
-

Sizing up Big Tech – IV
Out of the five usual suspects frequently fingered as Big Tech gang members, Microsoft (MS) takes the top spot, time-wise. Indeed, the company turned 50 last April, beating Apple by almost one full year. Many will associate such advanced age with dinosaurs, especially if we use Internet time as a benchmark. However, MS shows no…