In the coldhearted realm of disinformation, deepfakes seem to reign supreme, bullying all others around along the way. The fact that they have multiple personalities makes them even more insidious. Voice, text, images, and video content are among the most common, with combinations among them a frequent occurrence. Lip-syncing the voice of a targeted person and inserting it into a “do as I do” video is one shining and potentially harmful example. Here, the Imaginary meets the Real, almost replacing it. While image manipulation has existed since the invention of photography, deepfakes are in a different league. So how did we get there?
First, we must roll out the red carpet to welcome modern Machine Learning (ML) based on artificial Neural Networks (NNs). When the design of such networks includes multiple layers of neurons, the algorithms that support it are known as Deep Learning (DL) algorithms. Simplifying a lot, the core idea is that the sequentially interconnected layers of neurons (some with feedback mechanisms) can learn deeply even when starting from a basic input. The best example is image recognition, where the algorithm starts with a set of pixels and ends by understanding that the image in question is, indeed, a cat.
Modern deepfakes are the children of DL algorithms. Generative Adversarial Networks, or GANs, are among the most common algorithms deployed to create deepfakes. In a GAN, two different NNs operate in sync, competing in a zero-sum game. One, called a generative network, creates new (synthetic) data with statistical properties similar to those of the original set. It then feeds it to a discriminative network whose job is to detect (classify) whether the new data is real or fake. At the end of a successful training process, the discriminative network should be unable to distinguish real from fake, a process we could call negative learning. The generative network can thus create a fake image that the discriminative one classifies as accurate. Voilà, deepfakes!
In a previous two-part post, I described AI’s changes to computer programming. The rapid evolution of generative NNs has now introduced additional changes. For the most part, past ML algorithms were discriminatory. The central idea was to identify trends and patterns within a massive dataset to produce classifications or predictions based on statistical properties and conditional probabilities. Generative NNs are a very different animal, as their main job is to create new outputs mathematically and statistically linked to the data sets initially fed to the algorithm.
So, while my diagram in part two of the post holds for discriminatory NNs, it does not for generative AI. The figure below shows the most relevant changes we must consider for a complete picture. I have included a thumbnail of the previous graph in the lower right corner for reference.
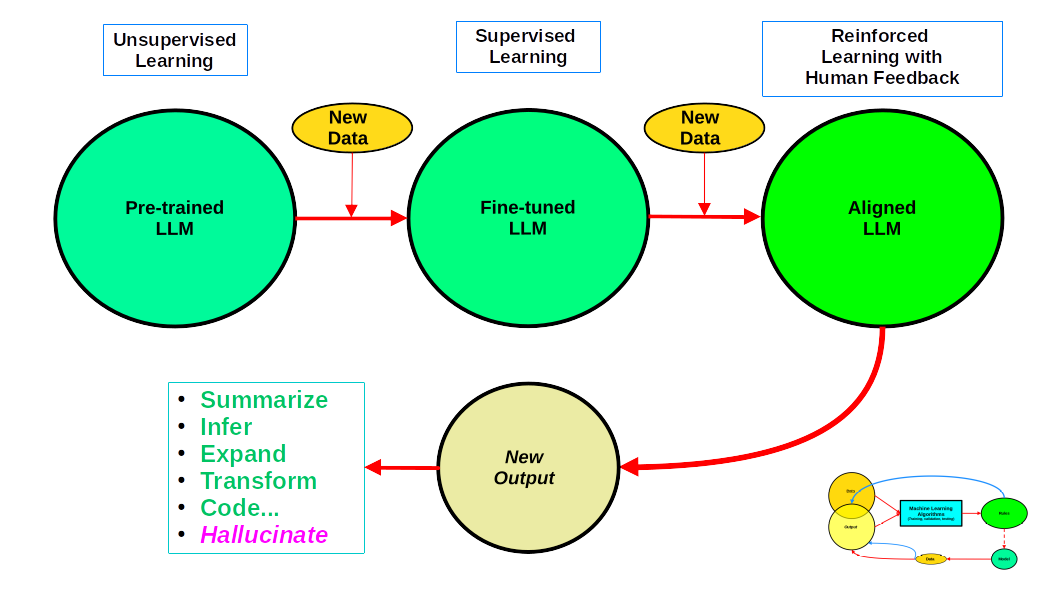 The most apparent change happens at the tail end of the process. Now, the model no longer needs new data to produce the final output. Instead, it responds to prompts from end users or computer programs using its APIs. Foundational GPT models such as ChatGPT or Bard can perform a series of tasks, listed in the lower left of the chart, relatively well. But they are also prone to hallucinations and errors, some of which might not be obvious to the human eye. And having the models themselves check for hallucinations or errors is still inadequate. Of course, they could “learn” more as they evolve, thus potentially minimizing mistakes.
The most apparent change happens at the tail end of the process. Now, the model no longer needs new data to produce the final output. Instead, it responds to prompts from end users or computer programs using its APIs. Foundational GPT models such as ChatGPT or Bard can perform a series of tasks, listed in the lower left of the chart, relatively well. But they are also prone to hallucinations and errors, some of which might not be obvious to the human eye. And having the models themselves check for hallucinations or errors is still inadequate. Of course, they could “learn” more as they evolve, thus potentially minimizing mistakes.
And it is precisely there, in the learning process, where the most significant changes take place. The first step yields the so-called pre-trained LLM. Most of us have repeatedly heard about its enormous size in terms of parameters (in the billions) and the massive amounts of data used to “pre-train” it using unsupervised learning. Up to here, this process matches the one described in my original scheme. But pre-trained LLMs do not perform well, so more training is needed. The second step is to use supervised learning and fine-tune the model with human-labeled data, then feed it to the LLM via prompts. Zero-shot, one-shot and few-shot just describe the number of prompts fed to the LLM to improve accuracy. The resulting fine-tuned model is called Instruct LLM. Parameter-efficient fine-tuning is an alternative, and one that might be computationally cheaper than Instruct fine-tuning. But both just repeat the data->ML->Model cycle.
The final step also uses labeled data, but with a twist. A data set containing prompts and possible responses (usually few-shot) is shared with humans, who must then rank the responses. Prompts and responses are reviewed by three or more humans, and the top-ranked response is selected accordingly. The updated dataset, including the newly labeled data, is then fed to the Instruct LLM using reinforcement learning. Every time the model selects the best response, it is rewarded accordingly to foster “deeper” learning. The final human-aligned model can now be made public.
Two critical issues must be highlighted here. First, note that the last step opens the door for having training processes where biases, hate and harmful stuff can be filtered out. In that case, the model will refuse to respond to specific issues. Conversely, bad actors can fine-tune one of the many open source LLMs available to do precisely that and have the model spit hate and call for harmful action. Second, note the crucial role of human labelers in the last step of the overall LLM training process. Questions such as Who are they? How were they selected? Where are they based? Are they multilingual? How much were they paid? Trainers should disclose this information to explore potential implicit bias. Unlike traditional labelers classifying images of, say, animals, here they are asked to use their brains to make an informed decision about a specific theme, topic, or issue.
Of course, not everyone needs to have an LLM to master most topics. The opposite is perhaps more relevant for most of us. Domain-specific LLMs can also be trained at a lower computational and financial cost. If I work in the health sector and want to use an LLM, I would be more than happy to have an expert health LLM that does not need to know about quantum entanglement. I can always use Wikipedia to check that out.
Raúl
