A recent paper published under the auspices of Google Health makes a case for using deep learning algorithms to improve breast cancer detection. The research has been positively received by most and widely publicized as yet another victory of intelligent machines over weak, dumber humans. Only a few have been critical for good reasons. In this post, I will explore the methodology used in the research to highlight other vital issues. But before I take the dive, let me first set the scene.
Background
Like education or justice, health is an information-rich sector, thus prone to rapid (not just digital) technology innovation and overall digitization. Unlike its peers, most, if not all, health-related services use a gamut of technologies, from simple thermometers and stethoscopes to noisy, giant MRI machines and jaw-dropping robotic surgeries. Recently, thanks in part to mobile technologies, consumer-centered health technologies have popped up, allowing us to monitor our health, from heart rates and blood pressure to mobile electrocardiograms and in situ diabetes testing. In fact, health technology has carved its own territory and provides fertile ground for deploying new technologies.
Diagnostic and treatment are the two overall areas that shape health services. The former is closely associated with prevention and early detection. In this light, annual checkups are a best practice, accompanied by a battery of tests that might end up including MRIs, computerized tomography scans (a.k.a cat scans) and mammographies. These and similar technologies have existed since the 1970s and thus predate the digital era.
At that time, Computer-Aided Diagnostic (CAD), born in the 1950s, was transitioning to its second phase by using expert systems, an early form of AI, to enhance diagnostic processes. By the 1990s, and given the limitations of expert systems and their eventual failure, CAD switched to data mining techniques supported by AI algorithms. In any case, recent research shows that CAD has not helped improve the diagnostic process, not breast cancer detection in particular.
Can Deep Learning (DL) make a difference? That is what the paper explores. Note that this is the third time AI has been enlisted to enhance health diagnostic outcomes.
Main Findings
I have read plenty of news media coverage of the paper’s core findings. Maybe these reports combine the results from other projects, as I found discrepancies in the population covered by the study in the UK and the US, among others. An odd occurrence indeed is that research data tables are available on the web – the paper is behind a paywall but can be read online as a PDF.
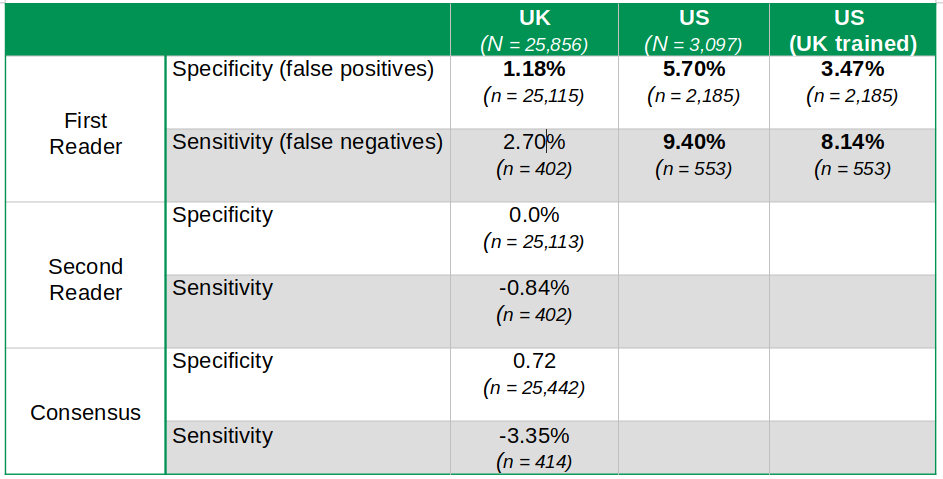
Table 1 summarizes the key findings. I have added the sample sizes for each of the results (n) and the size of the total population studied in each country (N). For the record, the UK’s overall sample size is almost nine times larger than that of the US.
Table 1

False positives refer to women wrongly diagnosed with breast cancer. False negatives include women with breast cancer who were given a clean health bill by mistake. The former causes tremendous stress and anxiety, while the latter could be lethal. Neither is really a good outcome. I am familiar with this as a few years ago, my wife was diagnosed with the disease. Fortunately, it was detected in its early stages and has had no recurrence. Notwithstanding, she is always under close scrutiny. During her last checkup late last year, she was asked to return for a second test to ensure everything was in order. It was. Can AI/DL help my wife and thus make a real difference here?
Going back to the table, each percentage represents the difference in performance between doctors and the deep learning algorithms. A positive number registers the rate of improvement made by DL. Cells in bold highlight findings are statistically significant at the 95% level – a fact most media coverage seemed to have missed or simply ignored. For example, the UK’s false negative improvement of 2.70% is not statistically significant and should not be used to make any conclusions about DL superiority. The paper suggests DL is not inferior but never says DL is beating humans in this rubric.
The difference in performance between UK and US outputs is outstanding. US DL diagnostic improvements are four times larger than those in the UK in the case of false positives – and slightly lower when applying a UK-trained model to the US data sample. So what is going on in the US then? Are US mammography readers less qualified than those in the UK?
I was unaware that in the UK, as in most of Europe, two independent readers are required to get the final results of any mammography. Moreover, if the two parties have a dissenting diagnostic, consensus among the parties must be reached, sometimes involving a third opinion. That is certainly not the case in the US, where only one reader is required. Interestingly, the DL platform does not outperform the second reader or the consensus diagnostic in the UK. DL algorithms are underperforming compared to the consensus reading by -3.35% regarding false negatives. However, this difference is not statistically significant, and the paper tells us that DL is thus not inferior.
In any event, we can safely conclude that DL can be most helpful in the UK as a labor-saving technology, just like many older technologies, starting with the steam engine. Apparently, the UK is facing a shortage of qualified readers. DL could undoubtedly help fill this gap. But in other countries where this is not the case, DL could end up displacing readers if embraced uncritically.
The evidence also suggests DL could indeed be an excellent complementary tool for UK readers and thus beneficial to expedite consensus and hopefully improve overall diagnostics. Note, however, that UK readers in the sample studied have a 98.5% false negative accuracy rate, as reported by the paper. Maybe this is why the DL platform could not generate any significant improvements here. The question is, how do we get to 99% or higher.
Raising Issues
Several media outlets and pundits have already flagged a few issues with this research. Not surprisingly, the code used cannot be shared as it is proprietary. Data sets for the US are unavailable, while UK data is unavailable upon request. The paper briefly mentions ethical issues related to the use of personal data and claims all is cool. No details are provided, however. My wife would love to know if her data would be used in some random AI study. She probably would agree, but neither I nor anyone else should decide for her. At any rate, all of the above criticisms are right on the money.
Nevertheless, I want to raise a few issues regarding the statistical procedures and significance of the paper’s findings. As mentioned above, the sharp difference in DL’s performance across the two countries is massive, showing a prediction improvement of over 300% for both sensibility and specificity in the US. The implication is that UK first readers are beating their US counterparts by a relatively large margin. That does not sound quite right to me. The US healthcare system is indeed expensive but is also of high quality. We need to poke a bit more deeply at how the data samples were designed and selected to ensure we are on the right track. Table 2 below presents a summary of the sample design from one of the tables in the paper.
Table 2
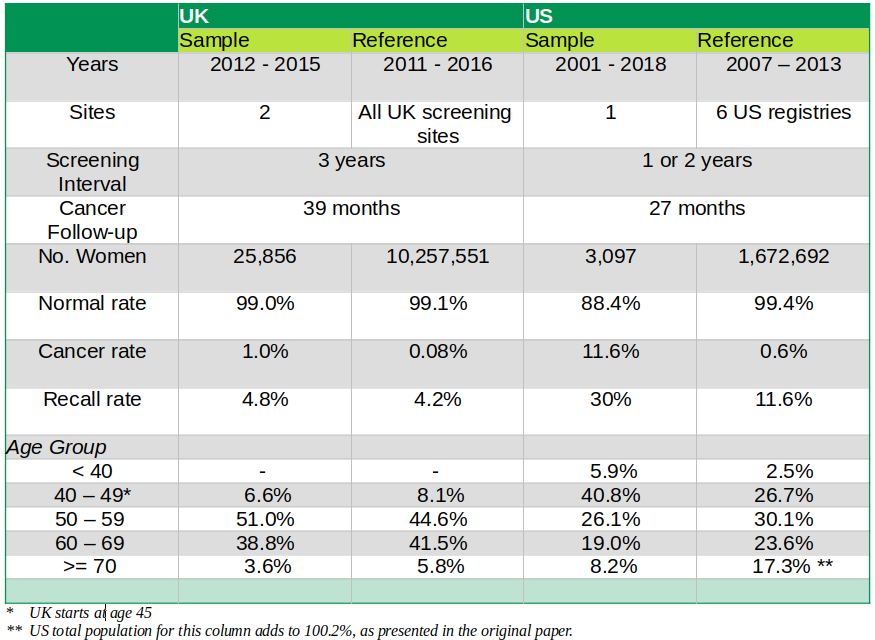
The reference column shows the data from the baseline populations selected by the study. Statistically, we could say these represent the actual population. That includes all sites in the UK, whereas in the US, it is much smaller and limited to six centers. We can thus assume that the UK reference population is very close to the actual population, as shown by the slight differences in mammogram diagnostics shown in Table 2. This is not the case in the US. Here, the differences between sample and reference populations are abysmal. We end up with two critical issues in the US. First, the sample is not representative of the reference population. Second, the reference population might not resemble the actual population.
The second issue is the period covered by the overall data. Once again, the UK data is more accurate as both sample and reference cover almost the same period. In the US, the sample covers 17 years and is thus much broader than the reference population, which only includes seven. This adds more bias to the US sample. In principle, the sample should cover the same period as the reference population to allow for appropriate statistical inference.
Third, the US sample comes from only one site, which questions the selection’s randomness. The paper suggests that data availability and convenience were important drivers for selection. That is certainly understandable, but the research should also have added the potential for bias and lack of randomness of the sample being used to avoid any sweeping generalizations – which is what most media ended up doing.
Lastly, the differences between the sample and reference populations for cancer diagnostics are incredibly significant in the US case. In the sample, almost 12 percent of women have cancer, which is nearly 20 times higher than those with a similar predicament in the reference data. The same goes for average diagnostic results – albeit the difference is not as vast. The paper estimates 95% confidence intervals for these numbers, and, in all cases, the range of the mean of the sample set does not include the actual mean of the reference population. The data by age groups show a similar statistical bias. Thus, it seems we might have the wrong sample here.
All of the above strongly suggests the US sample is not random nor representative of the overall population of women facing uncomfortable mammograms, analog and digital, every year. Moreover, comparing the results of the US sample with those of the UK also introduces bias as the data covers different periods. Ultimately, we can conclude that while the UK results are statistically significant, the same cannot be said about the US. In principle, the researchers should have tried to obtain a random sample in the US in the same fashion as they did in the UK.
The UK results, however, are not that impressive as DL was unable to outperform the system of two or more readers prevalent in the UK and Europe. Maybe the US should consider having more than one reader for complicated mammogram results and not put all its eggs into the DL basket.
I am sure my wife will love that to avoid being recalled for a second shot every time she gets her annual check. However, she is not betting on DL algorithms to change her predicament – at least not for now.
Cheers, Raúl
* Updated on 02/03/2020

Comments
One response to “Deep Learning and Breast Cancer: Improving Detection?”